





By Nicola Phillips, Contributing Writer, and John Belizaire, CEO
As 1991 drew to a close, Soviet troops were retreating from ex-satellite states and the U.S. was preparing to make a significant investment in a technology platform it deemed in the public interest. Within the span of three weeks in December, the Soviet Union collapsed and the U.S. Congress passed the High Performance Computing Act of 1991, popularly known as the Gore Bill (authored by then-Senator Al Gore).
Gore’s vision was that the bill would usher in an “information superhighway,” a term that gained momentum in policy discussions about the growing connectivity of information networks made possible by the Internet. Specifically, the Gore Bill helped fund the National Center for Supercomputing Applications (NCSA), founded five years prior at the University of Illinois. That funding from state and federal sources continues to this day, providing high-performance computing resources to researchers across the U.S.
(Fun fact: John’s first company was named after the Cornell Theory Center, one of the beneficiaries of the NCSA. It’s where he attended grad school with two of his five co-founders at the time.)
It was at the NCSA in September of 1993 that a team of programmers including Marc Andreesen created Mosaic, one of the world’s first graphical browsers. The release of Mosaic marked the beginning of the consumer web. As the prognosticators of the day claimed to anyone who would listen, this changed everything.
In November of last year, OpenAI released a demo version of ChatGPT, the earliest iterations of which had been invented seven years prior by a team of OpenAI engineers and researchers. Within five days of its release, ChatGPT boasted over one million users; within a month, it had 100 million.
These two inventions have followed similar timelines, and had similar implications for the future of computing, communications and, depending on who you ask, life as we know it.
If you began using the Internet after 1993 — as 99.99% of us did — then you’ve only ever used a graphical browser. Chrome, Safari, Firefox … these are all graphical web browsers. In the early 90s, however, the idea of a graphical browser was a revelation.
Between the development of the first web browser by Tim Berners-Lee in 1990 and the development of Mosaic in 1993, most web browsers were text-based. With text-based browsers, users had to type in verbal commands to retrieve information. Graphical browsers present web pages in a visual format, enabling users to scroll and click and visualize information.
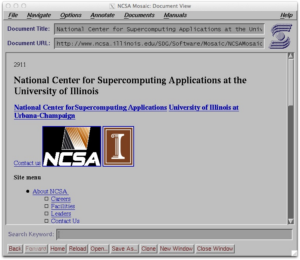
NCSA Mosaic 1.2 for Unix
Graphical user interfaces allow users to directly manipulate graphical elements — windows, icons, menus, pointers (the WIMP paradigm for short). Importantly, graphical user interfaces don’t require technical skills to maneuver. The logic underpinning interactions in these interfaces is inherently user-friendly, and visually appealing.
Chatbots like ChatGPT are powered by large language models, deep learning algorithms that are trained to process information based on predictive sequences. Broadly speaking, chatbots are a type of artificial intelligence, meaning they are machine applications exhibiting a near-human intelligence. Applications like ChatGPT, and indeed all large language models, are a subset of artificial intelligence called natural language processing.
On the face of it, chatbots are doing what search engines (which have been around since 1990) were designed to do, that is, answering questions. But the two frameworks approach this task of answering questions in very different ways.
Where search engines accept a query and spit back a list of relevant links, chatbots mine these links for (what they determine to be) the most relevant information and spit back a succinct answer to that query.
While a variety of algorithms affect the way information is ordered in a search, search engines do not give direct answers to a query (though Google search has been augmented in certain verticals to supplement links with directly relevant information). In general, search provides a bunch of options, leaving the “right” answer open-ended. Chatbots, true to their classification as artificial intelligence, seek to replace the human on the other side of that search interaction, providing a definitive response to the question at hand.
Mosaic triggered a boom in the Internet’s popularity by allowing non-technical users to access the web for the first time. Its user-friendly interface and low barrier to entry set off an explosion of innovation, and birthed what came to be known as Web 1.0.
ChatGPT appears to be doing the same thing for artificial intelligence. We are witnessing the birth of consumer AI.
Both applications have served to popularize their broader field. The core technology underpinning Mosaic and ChatGPT — graphical user interfaces and natural language processing, respectively — existed years, if not decades, before these applications were invented. The genius of these applications is that they brought their respective underlying technologies into the mainstream.
ChatGPT and its counterparts — Google’s Bard, Microsoft’s Bing Chat, and a slew of others — are changing the way we think about artificial intelligence. Before last fall, AI had been confined to purely technical spheres. Now, the general public — 150 million strong and growing — has access.
With this new accessibility comes huge potential and some frightening prospects for abuse. The most significant implications of these applications revolve around that crucial point of departure, pre and post a technology entering the mainstream. With ChatGPT, we are witnessing in real-time what others witnessed 30 years ago with Mosaic — how exposure to the mainstream leaves its mark on a technology.
Applications like Mosaic and ChatGPT provide platforms for a wide range of users to test existing (but to the public, novel) technologies, voice their opinions on them, and perhaps capitalize on these learnings to iterate on the original concept. Once available to the general public, and used at volume with a wide diversity of interactions, how do the technologies morph and change? What are the unintended consequences?
To be continued…


